Three text sentiment analysis methods — and why ours is better

Sentiment analysis is a core text analytics capability that every organization needs to master to build strong brands and even stronger relationships with consumers. Categorizing consumer comments by sentiment has been done for quite a few years, but this seemingly straightforward task is anything but.
Surprisingly, many organizations and text analytics systems still employ the simplest and most limited approach to categorizing sentiment. Here’s how three of the most commonly used sentiment analysis techniques work — and why they all fail to produce actionable insights.
1. Word-based categorization (aka word spotting)
The most straightforward approach to sentiment categorization is to assign words a positive or negative value, called sentiment weight. You then identify any word(s) in a consumer comment that might be important and simply add up the sentiment weights of each word to determine the comment’s sentiment score.
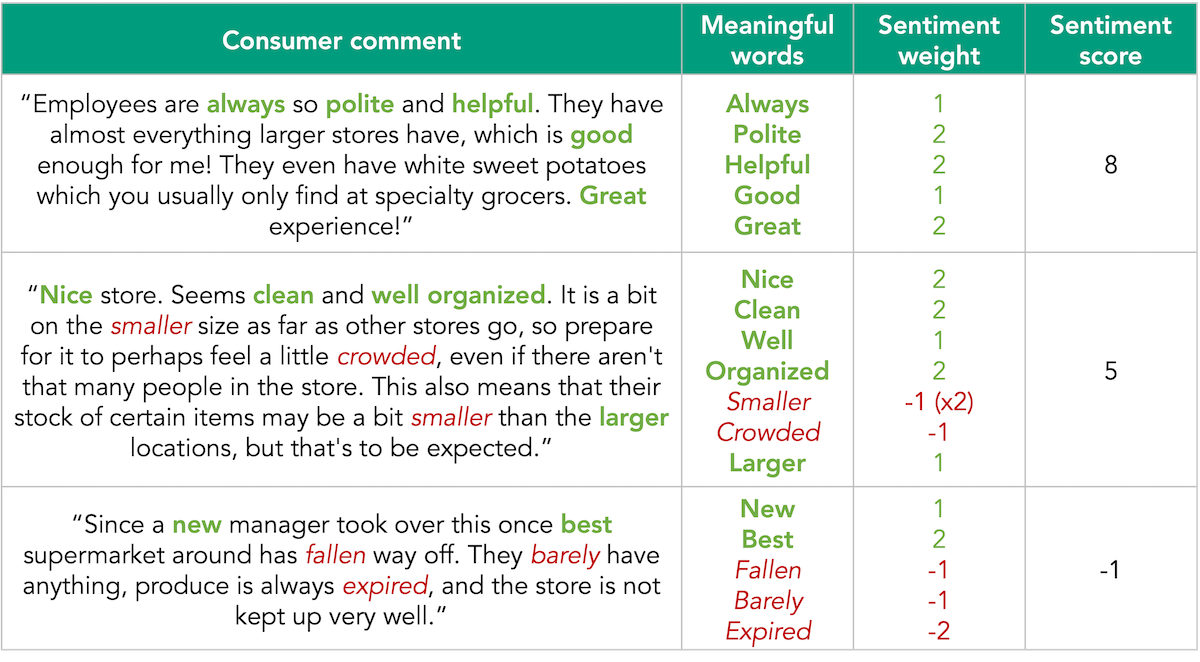
Interpreting the results can be ambiguous
Notice that word-based categorization does not actually identify sentiment. The method depends on a carefully controlled dictionary of words and weights. The resulting score requires a great deal of interpretation and can be impacted by longer comments (more words can equate to exaggerated scores). A meaningful difference between a sentiment score of 8 and 5 is not defined. While -1 seems to indicate negative sentiment, there’s still quite a bit of positive in the text. Additionally, a slight change in the dictionary weights could produce a very different result.
Techniques exist to address some of these concerns. Some systems assign weights to two- or three-word phrases, not just individual words. While it’s an improvement over single word weighting, it introduces a much larger dictionary of words and phrases that must be carefully adjusted on a use-by-use basis. Ultimately, this technique can still be useful in limited scenarios but is subject to error and incurs a high degree of interpretation.
2. Rule-based categorization
Rule-based approaches have been used for categorizing sentiment within most text analytics tools for many years. This approach builds on the word spotting technique by introducing natural language processing (NLP) rules to improve the quality of the results. Rules usually look something like:
- Always NEAR polite = POSITIVE (+2): When the word “always” is near the word “polite,” the combination is valued at 2.
- Not NEAR always NEAR polite = NEGATIVE (-2): When the word “not” is near the words "always" and "polite," the phrase is valued at -2.
Text analytics systems using a rule-based approach can quickly process hundreds, thousands, or even millions of consumer comments. This method can alleviate manual labor if the accuracy concerns are understood and monitored.
Rules must be monitored and maintained
Rule-based approaches are far more powerful than simple word spotting but require a sizable setup effort to assemble the rules. Text analytics companies often have pre-built collections of these rules to help organizations get started. However, to maintain accuracy, these systems require fine-tuning for each use case to address the nuances of how words are used in varying industries, like utilities or grocery retail, or product categories, like electronics or apparel.
Nonetheless, this still leaves the challenge of interpreting the output: What does a sentiment score of +2 mean?
3. Machine learning or artificial intelligence pattern detection
Machine learning (ML) and artificial intelligence (AI) tools are pattern-detection and pattern-matching systems trained to categorize text. ML/AI-based systems can detect patterns in word sequence and distribution to produce high-quality classifications. These systems are typically trained on vast quantities of text by feeding them sets of “labeled” comments:
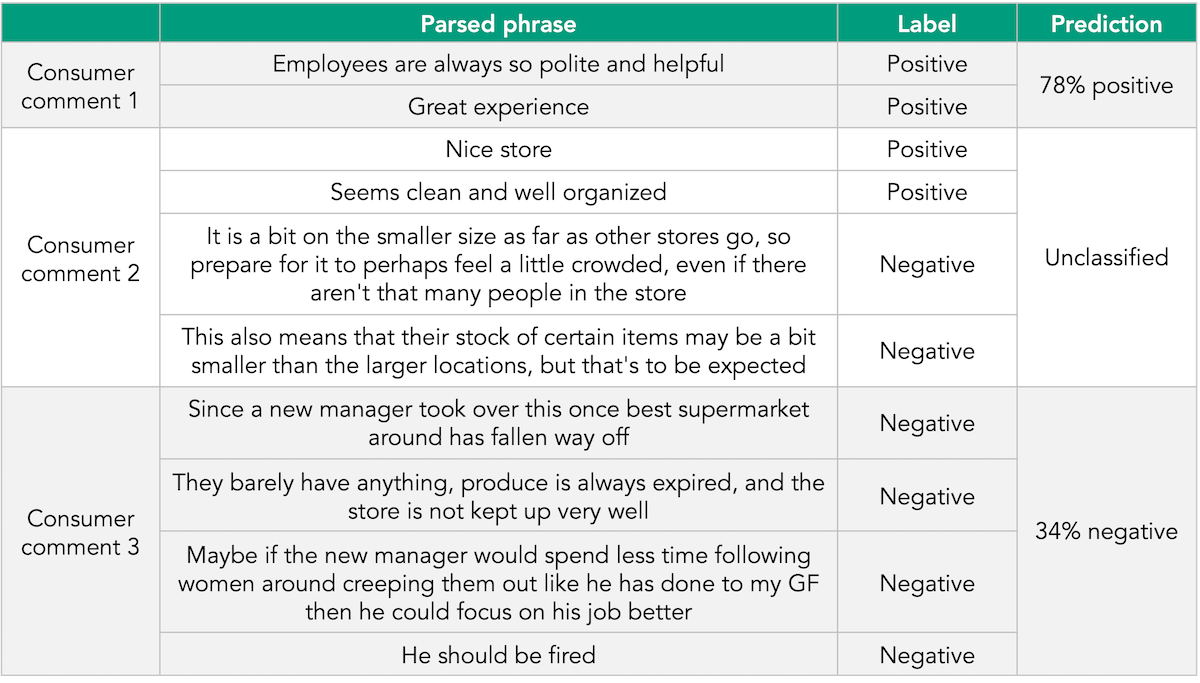
Once fed large collections of comments, ML/AI systems learn to identify specific patterns of words that appear in a given sequence (such as “barely, have, anything”) or in a group (“expired” + “produce”). The system can reapply that learning to new comments that require analysis. With sufficient training data, these systems can produce highly accurate predictions for sentiment.
What’s not to love about machine learning/artificial intelligence techniques?
While ML/AI techniques are robust and generally surpass word spotting or rule-based approaches, they have their pitfalls:
- They are limited by the training data they are fed. Mislabeled data can skew results.
- Training on nuanced industry/brand jargon is rare, which means they usually misclassify or fail to classify many texts that contain such jargon.
- When the labels are incorrect, it can be difficult or impossible to understand how the ML/AI reached its conclusion.
- They produce statistical predictions for how likely a text is to be positive or negative. This leads to similar ambiguities as with rules/word spotting. What does a likelihood of 56% positive and 44% negative mean?
- They tend to fail to produce an obvious sentiment assignment for a larger portion of the comments, leaving many comments unclassified or hard to classify.
- They require some judgment when assigning a final sentiment to a piece of text.
 Unstructured data is complex and so are the tools used to analyze it. Make sure you’re not falling for one of these five common text analytics misconceptions — but here's what to do about it if you are.
Unstructured data is complex and so are the tools used to analyze it. Make sure you’re not falling for one of these five common text analytics misconceptions — but here's what to do about it if you are.
How to address the shortcomings of text sentiment techniques
Remove the room for interpretation
Separating sentiment (the feeling) from intensity (the numerical value) produces results that humans can quickly identify with and reduces the ambiguity often found with other methods. “Strongly positive” or “weakly negative” are highly subjective, lead to a great deal of misunderstanding, and create barriers to a greater understanding of consumer opinions.
Rather than having to interpret and differentiate between numerical values, these outputs can be fed into a final decision-making system that assigns simple, human-centric classifications:
- Positive
- Negative
- Mixed
- Neutral
- Unidentified
Keep the human behind the comment in mind
While not immune to misclassifications, the output is a label that humans can quickly identify with and enables in-depth, nuanced analysis and discovery of what consumers are conveying. Mixed sentiment is essential as it properly expresses the reality of how consumers often share their opinions, like in these real-world comments from consumers.
“Great store, but often are low on stock.”
“The long lines are worth it because of the awesome prices.”
“It took too long to fix my issue, but the staff was courteous throughout the whole process.”
Separating sentiment from intensity allows analysts to understand how consumers express themselves. It uncovers a critical understanding of how we use language to express opinions: Most genuine, sincere human expressions of opinion express mixed sentiment.
How Bellomy is enabling a better future for text sentiment analysis
While the science of text analytics continues to evolve, Bellomy’s approach of separating sentiment from intensity achieves the best human-centric results for both the consumer and the analyst. Embracing a massive rule-based system combined with an NLP-based statistical model and an AI/ML mechanism produces a human-interpretable classification — positive, negative, mixed, neutral, or not identified — for each piece of text.
Our secret sauce, however, lies in human curation. As with all natural language tasks, our approach has some uncertainty, and misclassifications can occur. When they do, we empower both users and our dedicated text analytics staff to correct those misclassifications, which then make their way back into the process to improve future classifications.
How can text sentiment analysis impact your organization?
The ability to quickly discern consumers' overall sentiment enables the rapid discovery of nuanced consumer feedback, often revealing meaningful insights into strengths, weaknesses, or potential crises. It can even uncover critical business opportunities to elevate a brand beyond its competitors.
With Bellomy’s Text Analytics tool, researchers get reliable, interpretable, and believable output — even when it comes to non-survey feedback like social media, online reviews, and more. The tool eliminates time spent reading and categorizing open-ended feedback. This allows users to spend their energy where it matters: identifying the root cause for negative sentiment, pinpointing drivers of positive sentiment, and uncovering what’s holding consumers back when they express mixed sentiment.
Get a free demo of Bellomy’s Text Analytics tool to see how your organization can use it to uncover powerful sentiment insights.
- text analytics